gcpdiag Architecture
Overview
gcpdiag exclusively uses public APIs and is designed to be a sort of test suite or linter, where each lint rule verifies a single aspect of a GCP project that might be problematic. Example: the IAM permissions of a service account are not set correctly so a GCE instance can’t send logs to Cloud Logging.
The high-level architecture of gcpdiag looks as follows:
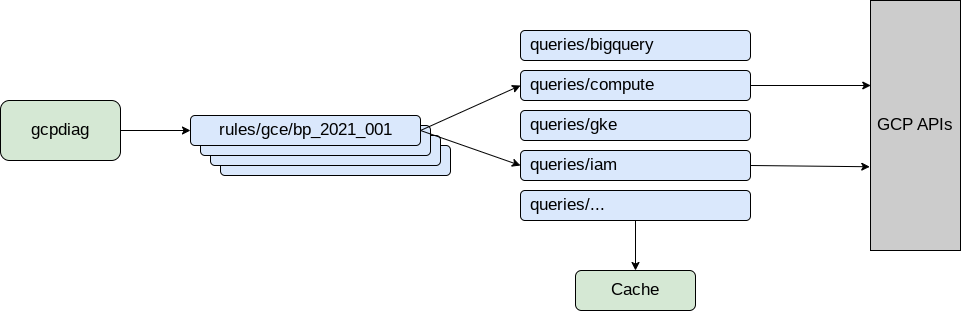
Every lint rule (e.g. gce/bp_2021_001 above) is represented as a Python module
that registers to the main command gcpdiag with some metadata about the lint
rule, and the implementation of a run_rule() method to run the rule checking
code. Writing new rules should be as easy and quick as possible, to foster a
lively and up-to-date set of rules.
Queries Modules
Any queries that are done to the GCP API are done via so-called “queries” modules, which encapsulate all the queries that are required by gcpdiag lint rules. The queries are separated from the lint rules to facilitate code reuse and also to improve performance. Most queries done by the query modules cache their results, so that subsequent queries are very fast. This is necessary because if every rule needs to do GCP API calls every time that it needs to verify something, the lint command would take too long to run.
The queries modules are also used to make the implementation of the lint rules as simple as possible. Also, we strive for very good test coverage only for the queries modules and not for lint rules.
Context Objects
gcpdiag allows users to select the resources that should be inspected by specifying the following criteria:
- Project id (mandatory, e.g.:
my-project-id) - Regions list (e.g.:
us-central1,europe-west2) - Labels list (e.g.:
{'environment': 'prod'},{'environment': 'pre-prod'}
When all three are specified, all must match (the values in the lists are ORed).
models.Context (see:
models.py) represents the
filter given by the user and is used in queries modules to select resources.
Resource Objects
Queries modules generally return objects that implement the
models.Resource abstract class. A Resource object represents a single
resource in GCP and must have these three methods:
project_id(property)full_path(property) - returns the full path of this resource (e.g.:projects/gcpdiag-gke-1-9b90/zones/europe-west4-a/clusters/gke1)short_path(property) - returns the short name for this resource (e.g.:gcpdiag-gke-1-9b90/europe-west4-a/gke1)
Queries modules provide functions that generally require as input a Context
object and return a dictionary or list of Resource. It is the responsibility
of those functions to implement the filtering according to the provided context.
For example,
gke.py
provides:
def get_clusters(context: models.Context) -> Mapping[str, gke.Cluster]
Resource objects provide abstraction to retrieve attributes of these resources,
so for example for a gke.Cluster object you can for example use the
has_logging_enabled() method to check whether logging is enabled:
for c in gke.get_clusters(context).values()
if c.has_logging_enabled():
...
Note that we don’t strive to have a complete model for all resources in GCP, because that would be way beyond the scope of this project. We are only implementing the functionality that is needed in linting rules, nothing more. Lint rules are not allowed to access the APIs directly and are also discouraged to access internal resource representations.
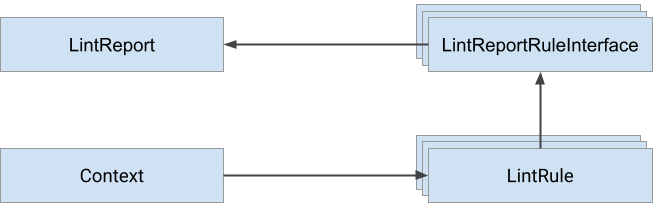
LintReportRuleInterface
Lint rules need to report their findings back to the user and we want a way to do that that is both very simple from a rule-implementation point of view, but also allows flexibility in structuring the output in a beautiful way in the console, or also to provide alternative output formats such as JSON or HTML.
The way we achieve that is by abstracting all the lint rule reporting into an object, that is passed to the lint rule executor, and that is used to report back the findings. The interface looks as follows:
class LintReportRuleInterface:
def add_skipped(self,
resource: Optional[models.Resource],
reason: str,
short_info: str = None):
def add_ok(self, resource: models.Resource, short_info: str = ''):
def add_failed(self,
resource: models.Resource,
reason: str,
short_info: str = None):
Rule modules are given a Context object to determine what they should analyze, and a LintReportRuleInterface object to report back their findings. The findings can be for any resource one of:
- Skipped (the rule is not relevant / can’t be checked)
- OK
- Failed
The following diagram shows the information flow:
Rule Modules
Creating a new rule should require not more than a page-length of code, because all the complex querying logic should be implemented in the reusable queries modules. Each rule implements the rule checking logic as Python functions:
-
run_rule(context: models.Context, report: lint.LintReportRuleInterface):
This function is the main function used to run the rule logic on a certain context (list of projects + resource selectors). The function is supposed to provide results about the rule evaluation using the report interface.
-
prefetch_rule(context: models.Context):
Each run_rule function is called in order of rule execution, one function at a time. To minimize the total runtime of gcpdiag, rules can implement the
prefetch_rulefunction to do data collection before the rule is actually started. The difference is that no reporting is possible: that will need to happen in therun_rulefunction. Theprefetch_rulefunctions are called in parallel using multiple worker threads. -
prepare_rule(context: models.Context):
The
prepare\_rulefunction is similar toprefetch\_rulebecause it is also used to pre-load data before the rule is executed. The difference is that theprepare\_rulefor all rules is called first, and not in parallel. This is useful for tasks that need to run as early as possible, but don’t actually take a long time to complete. Currently the only use-case is for defining logs queries.
Rule modules should never access the API directly, but always use query modules instead. This ensures proper testing and separation of concerns. Also, this way we can make sure that the queries modules cover all the required functionality, and that the API calls are cached.
You can see the documentation of this rule here and the github logic for this rule here
Example code:
"""GKE service account permissions.
Verify that the Google Kubernetes Engine service account exists and has
the Kubernetes Engine Service Agent role on the project.
"""
from gcpdiag import lint, models
from gcpdiag.queries import crm, gke, iam
# defining role
ROLE = 'roles/container.serviceAgent'
# creating rule to report if default SA exists
def run_rule(context: models.Context, report: lint.LintReportRuleInterface):
clusters = gke.get_clusters(context)
if not clusters:
report.add_skipped(None, 'no clusters found')
return
project = crm.get_project(context.project_id)
sa = 'service-{}@container-engine-robot.iam.gserviceaccount.com'.format(
project.number)
iam_policy = iam.get_project_policy(context.project_id)
if iam_policy.has_role_permissions(f'serviceAccount:{sa}', ROLE):
report.add_ok(project)
else:
report.add_failed(project,
reason=f'service account: {sa}\nmissing role: {ROLE}')
Metadata about the rule is determined as follows:
- Product: directory where the rule is placed. Example:
gke. - Class: filename, e.g.:
gke/bp_2021_001_cloudops_enabled.py-> class BP. - Id: product+class+id uniquely identify a rule. Also determined by the filename, same as class (see above).
- Short description: the first line of the module docstring is the rule short description, this is what appears in the rule line in the report.
- Long description: docstring after the first line. When a rule fails, the long description is printed as well.
Rule Execution
gcpdiag lint is a general “broad” diagnostics tool that runs as many diagnostic test as possible, so that it can detect issues that you are completely unaware of. GCP API calls can however take a considerable amount of time to complete, so in order for the total runtime not to be too long, two techniques are used: caching and parallel execution.
Caching takes care of making sure that the same query is never executed twice, and is explained more in detail in the next section.
Parallel execution is implemented as follows:
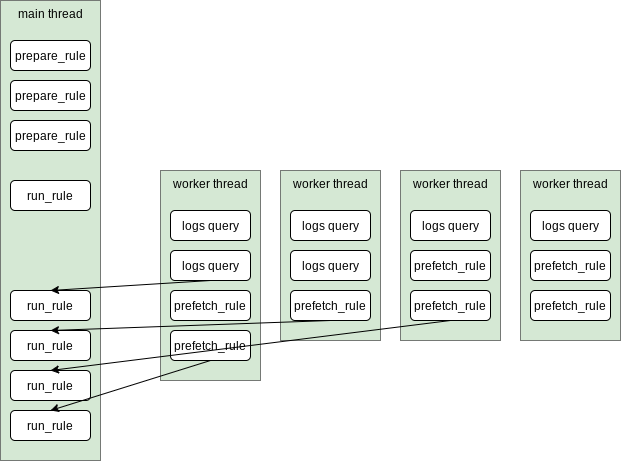
- First, the
prepare_rulefunction of each rule is called (if the rule defines one). These are called serially in the main thread, and are supposed to be quick to execute. The main use case is to prepare some aggregated querying that will need to happen later (only for logs at the moment). - Worker threads are started (currently 10) and execute first all required
logging API queries, then all
prefetch_rulefunctions that rule can define. - Immediately after starting the worker threads with logs and prefetch_rules,
the main thread continues and starts executing the
run_rulesfunctions in the right order (alphabetically sorted) and synchronously starting to print the report. - The rule scheduler makes sure that any dependent logging or prefetch_rule
execution that is required by a rule completes, before starting the rule
(e.g. this is shown in the diagram where the second
run_ruleis executed only after a certain logs query has finished).
Caching
Every rule is independent and uses the queries modules to query for example the list of GKE clusters in a project. This makes the implementation of rules easier, but since multiple rules require the same data, this would mean fetching for example the list of GKE clusters multiple times. In order to avoid doing the same query multiple times, the results of API calls are cached either to memory or to disk.
Considering that the amount of data can be significant and in order to keep the memory consumption of gcpdiag at reasonable levels, generally caching will be done to disk, but then most cached data will be deleted once gcpdiag has finished executing.
The implementation uses the diskcache Python module, which uses Sqlite under the hood to provide a very quick and featureful caching implementation.
To make the implementation as streamlined as possible, we have implemented a
function decorator called caching.cached_api_call:
@caching.cached_api_call
def get_clusters(context: models.Context) -> Mapping[str, Cluster]:
cached_api_call is very similar to functools.lru_cache, with the following
differences:
- uses diskcache, so that the memory footprint doesn’t grow uncontrollably.
- uses a lock so that if the function is called from two threads simultaneously, only one API call will be done and the other will wait until the result is available in the cache.
Parameters:
expire: number of seconds until the key expires (default: expire when the process ends)in_memory: if true the result will be kept in memory, similarly to lru_cache (but with the locking).
API Libraries and Authentication
We use the low-level google-api-python-client and not the new “idiomatic” client libraries because only the API library has full support for all GCP APIs (through discovery).
Authentication is done either with the Application Default Credentials (via gcloud command-line) or with a key file for a service account.
The
apis.get_api
function is used to retrieve the API interface and also takes care of doing any
necessary authentication step.